

Appropriate Intelligence: Responsibly Applying AI in the Real World
We are currently at peak popularity when it comes to artificial intelligence — at least, if you believe that Google’s global search data is a valid proxy for interest in this subject. What is noteworthy is that until only a few years ago searches for this topic were declining. So, what changed? Specifically, the amount of searches for machine learning (ML). Despite renewed interest, two of the most popular and useful forms of machine learning, support vector machines and linear regressions, have not seen commensurate increases.
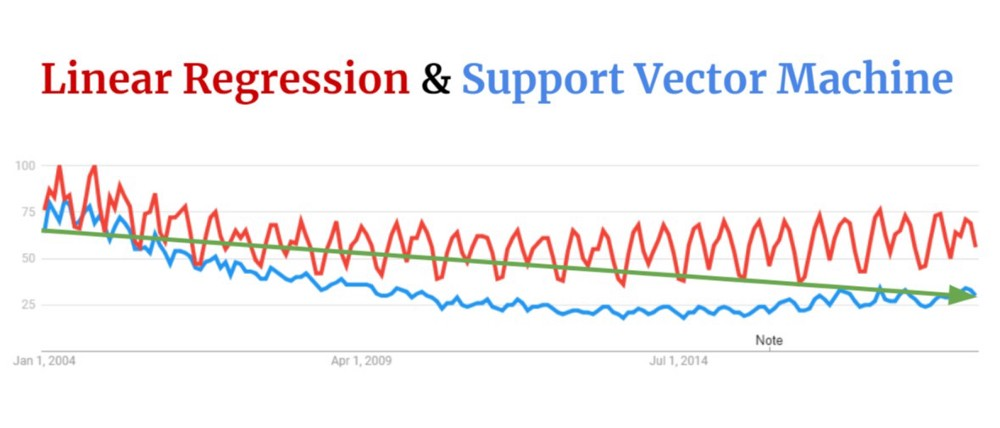
So what is getting all the machine learning love? Neural networks! Perhaps this was to be expected given how many impressive examples we have seen in recent years. From translation to board games, neural networks have given us unprecedented abilities to solve problems that had long been considered intractable. Adding to this excitement are machine learning frameworks such as Tensorflow and PyTorch that enable anyone to build a neural network with a few lines of code. People can do this with only a basic grasp of the subject.
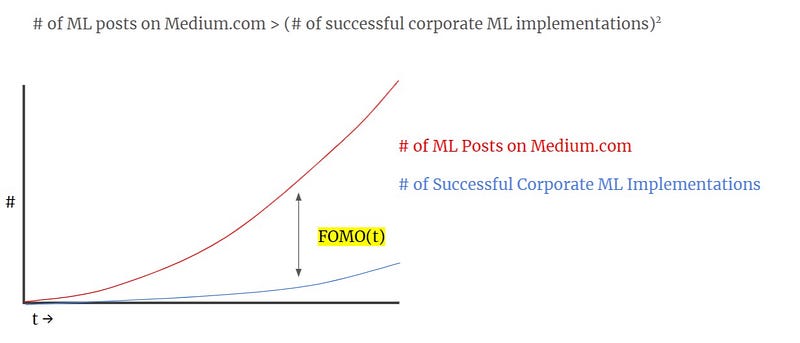
However, maybe we should temper our enthusiasm. Without prior experience in training neural network it is incredibly easy to overfit your models. This is greatly exacerbated by people who lack the fundamental understanding of why splitting data into training, validation, and testing sets is required. As neural networks are an advanced type of machine learning, it can be difficult to explain to end users how the model is making decisions. Despite these realities, it can feel like “everyone else is doing AI successfully.” Maybe because there are far more posts about ML than successful implementations?
So how should we think about implementing artificial intelligence solutions? I propose looking through three lenses. The first is the end user lens, or to think like a product manager. This lens considers the value that will be created by the application of AI. The reality is that in many cases classical statistics can solve a problem, and if ML is required, then simpler models will do the job just as well as neural networks. While in certain cases (e.g. CNNs) you have little choice in using a neural network, it is usually worth assessing this beforehand.
The second is the algorithm lens, which considers whether you have chosen not only the simplest model, but if you have trained and architected it in a way that makes sense for this particular problem. Thinking like a machine learning engineer, can you explain why you made the choices you made? Do you know what the impact of various parameters is on your model’s overall accuracy? Beware of software applications that offer a “neural network” button. The default settings are dangerous at worst and computationally wasteful at best.

The third and final lens is the data lens. This asks you to consider what data you have available and how you are using this in the context of the model. You have to think like a data engineer and a data ethicist. Do you have enough data to effectively train your model? Have you performed a train/validate/test split; are you using cross validation where appropriate? Most importantly, have you ensured that your data is representative and free of as many biases as possible? While eliminating all biases is difficult, they can be minimised.
Developing and deploying artificial intelligence solutions into production is one of the most powerful ways to generate both value in your organisation and to improve the experience of your customers. However, this only holds true if this is an appropriate use of intelligence and has been considered from a user, an algorithm, and data perspective. Mindfulness, but for machines.
— Ryan

Q* - Qstar.ai Newsletter
Join the newsletter to receive the latest updates in your inbox.


{kind=link}